Biz/Browserコア開発エンジニアを募集しています
しばらくブログを書けずにいたら、あっという間に年が変わって2月末になってしまいました。今年もよろしくお願いいたします。
今日は人材募集の記事を書きます。
私が所属している株式会社オープンストリームでは、現在ちょっと特別なソフトウェアエンジニアを募集しています。かなり上級レベルの人が対象になりますが、この後説明するとおり、非常にやりがいのある仕事なので、我こそはと思うかたは是非私( https://www.facebook.com/hideo.terada.5 または terada.h@opst.co.jp )までご連絡ください。
どんな仕事内容?
やっていただきたい仕事の内容は Biz/Browser 本体および周辺ツールなどの開発です。Biz/Browser『を使った』アプリ開発ではありません。Biz/Browser 『そのものを』開発する仕事です。
この開発業務は、以下に述べるようにコンピュータ・サイエンスの核心ともいえる知見が必要なもので、技術レベル・知識レベルとしてかなりレベルの高いものが必要です。
![]()
なぜ今募集する?
今回、製品ラインナップのさらなる拡充のためエンジニアを増員することになりました。
Biz/Browserとは?
Biz/Browser は、主に業務系プロフェッショナル UI作成に特化したアプリケーション開発ツールであり、以下の要素を全て当社で 企画・開発しています。
この仕事の面白さ、やりがい
上記のように、Biz/Browserの開発は、一個のソフトウェア開発環境のエコシステム全体を企画、設計、実装していくという、ある意味で壮大な仕事です。
フル機能のプログラミング言語そのものの設計から始まり、それを動作させる仮想マシンや、コンパイラ、開発ツール、ライブラリまでを自分たちで作っていくという仕事は、国内はもちろん、海外でもなかなか体験できるものではないと思います。
これに携わるエンジニアにとって、ソフトウェア技術者、コンピュータ技術者としての真の力量が問われる仕事であり、大きなやりがいと面白さを感じることでしょう。
また、Biz/Browserは、これまで 1700社以上の納入実績 があり、生産・物流・流通や金融など、社会を支える産業系のお客様にご愛用いただき、また育てていただいた製品です。
自分たちが作った製品のユーザからの声を聞き、それを製品に反映していくことができるのは、開発者にとって大きな喜びとなると思います。
求める人物像
以下のような特徴例のどれかに該当する方なら、この仕事に適任である可能性が高いです。
例:
- とにかくプログラミングやコンピュータが好き
- 新しい知識や技術を吸収するのが得意
- 普段から、色々なプログラミングパラダイムを意識している(構造化、オブジェクト指向型、関数型、論理型など)
- 関数型プログラミングを使用したことがある。(Lisp, Scheme, Prolog, Haskel, Erlang など)
- C++のテンプレートでメタプログラミングするのは日常である
- コンパイラの吐き出したアセンブリコードを解析したことがある
- コンパイラやインタープリタなど、言語処理系を自作したことがある
- テキストエディタやグラフィックエディタを自作したことがある
- JPEGのデコーダを自作したことがある
- H.264のエンコーダを自作したことがある
- デバイスドライバや、ファームウェアなど、OSまわり・低水準プログラミングを経験している
- リアルタイムOS上での開発を経験している
- アクション系のゲームや、ロボット等のリアルタイム制御システムを開発したことがある
- ゲームをやるよりも、ゲームを作る方だ
- マルチスレッドプログラミングの勘所をつかんでいる
- 状態遷移図で設計するのは当たり前である
- 機械語ダイレクトは面倒だけど、アセンブラなら普通に使う
- チューリングマシン、チューリング完全について説明できる
- シャノンの情報理論を説明できる
- ノイマン・アーキテクチャと、ハーバード・アーキテクチャの違いについて説明できる
- バッファオーバーフロー攻撃の原理について説明できる
- 上記のような経験はないが、どういう内容か見当がつくし、やればできる自信がある。
最後に
いろいろと書きましたが、一番大事なのは過去の経験ではなく、この仕事のやりがいに共感していただき、今後我々とともに未来に向かって成長していく意欲のある方です。Biz/Browserの開発は簡単な仕事ではありません。絶えざる努力と勉強が必要な仕事です。しかし、だからこそ大きなやりがいがある仕事だとも思います。我こそは!と思われるかた、是非ご応募よろしくお願いいたします。
(応募先 https://www.facebook.com/hideo.terada.5 または terada.h@opst.co.jp)
ディープラーニング論文読解メモ:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (DCGANによる教師なし表現学習)
今日もコツコツとDeep Learningの勉強をしています。以下、論文を解読した際の個人的な抄訳メモです。訳あって、いまさらDCGANです。自分の興味のないパートはすっ飛ばしています。悪しからず。
Abstract
- CNNを用いた教師なし学習は、いまいち注目されていない。
- 本論文では、DCGAN を紹介する。これは、ある構造的な制約を持ち、教師なし学習への強力な候補であることを示す。
- Generator(G) および Discriminator(D) の双方において、DCGANは、オブジェクトのパーツからシーンへとつらなる階層的な表現を学習していることを示す。
1. Introduction
- 大規模なラベルなしデータ・セットからの再利用可能な特徴表現の学習は、活発に研究されている。
- コンピュータビジョンの文脈では、事実上無制限のラベルなし画像やビデオを良好な中間表現の学習に使うことができ、その後それは様々な教師あり学習タスクに活用される。たとえば画像分類など。
- 良好な画像表現の構築の一つの手段が、GANのトレーニングによるものであることを提案し、その後、教師ありタスクのための特徴抽出器として Generator と Discriminator の部品を再利用することを提案する。
- GANは学習が不安定であることで知られ、しばしば 意味のない出力をするGeneratorを生成するという結果に終わる。
- GANの学習とは何か?そして多層GANの中間表現はどうなっているのか?について理解し可視化しようと試みている研究報告はとても限られている。
- この論文では、以下の貢献を行った。
- Convolutional GAN のたいていの問題設定において学習を安定させるような構造的トポロジーについての一群の制約を提案し評価する。このクラスのアーキテクチャを我々は Deep Convolutional GANs (DCGAN)と呼ぶことにする。
- 学習済みの Discriminator を、画像分類タスク用に用いて、他の教師なしアルゴリズムに匹敵する性能であることを示す。
- GANで学習したフィルターを可視化し、特定のフィルターが特定のオブジェクトを描くように学習していることを実証的に(empirically)示す。
- Generator が興味深いベクトル演算プロパティを持ち、生成されたサンプルの様々な意味的な品質を、そのプロパティによって容易に操作できることを示す。
2 Related Work
2.1
2.2
3 Approach and model architecture
- 画像をモデル化するためのCNNを使ったGANのスケールアップのこれまでの試みは成功してこなかった。
- 我々も、よくある教師ありの方法でCNNでGANをスケールしようとして、困難にぶち当たった。
- しかし、広範なモデルの探求ののち、あるアーキテクチャファミリーを特定した。それは一定の範囲のデータ・セットに渡って安定したトレーニングができ、より高い解像度やより深い生成モデルにも適用できる。
- 我々のアプローチの核となるのは、CNNアーキテクチャに対する3つの変更である。
- 第1は全コンボリューションネット(Springenberg et al.,2014)である、それは(maxpoolingのような)決定論的空間プーリング関数を、ストライドコンボリューションに置き換えて、そのネットワークが自己の空間ダウンサンプリングを学習できるようにしたものである。
- この方法は generator に用いていて、generatorが空間アップサンプリングを学習できるようにする。そして、discriminator にも用いる。
- 第2はコンボリューション特徴のトップにあるフルコネクト層を削除する方向性である。
- これの最強の例は、グローバルアベレージプーリングである。それは最先端の画像分類モデル([Mordvintsev] et al.)で使用されている。
- グローバルアベレージプーリングは、モデルの安定性を高めるが、収束スピードを阻害することを我々は発見した。
- 最も高いコンボリューション特徴群を、genrator と discriminator それぞれの入力と出力に直接接続するという折衷案は上手く動いた。
- GANの最初の層、それは正規分布ノイズZを入力とするが、それは単なる行列の積なので、フルコネクトと呼んでも良いかもしれない。しかしその結果は、4次元のテンソルに reshape されて、コンボリューションスタックの始まりとして使用される。
- discriminator に対して、最後のコンボリューション層は、フラット化され、そして一つのシグモイド出力に接続される。(図1にモデルアーキテクチャの例を示す。)
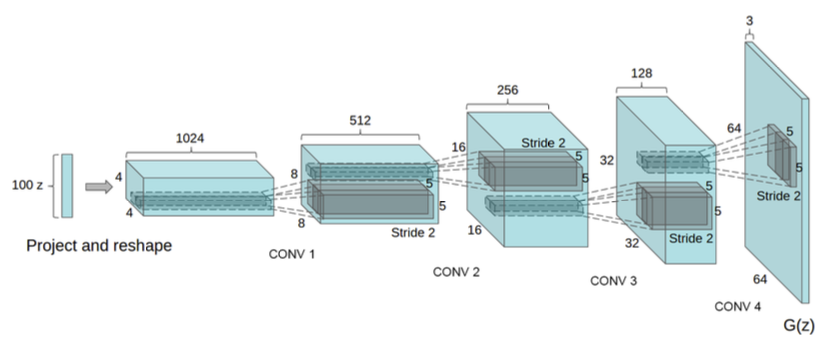
- 図1 LSUNシーンモデリングに用いたDCGAN generator
- 第3は、バッチノーマライゼーションである。それは各ユニットへの入力を平均0分散1に正規化させることで学習を安定化させる。
- これは、貧弱な初期化によって起きるトレーニングの問題の扱いを助け、深いモデルにおける勾配の伝搬を助ける。
- これは、全サンプルを一つのポイントへと潰してしまう generator という、GANに見られる共通する失敗モードを抑制しながら、深い generator が学習を始めるために重要であると証明した。
- 直接的に全層にBNを適用すると、サンプルオシレーションやモデルの不安定化をまねく。これは generator の出力層と、discriminator の入力層にはBNを適用しないことで防げた。
- 第1は全コンボリューションネット(Springenberg et al.,2014)である、それは(maxpoolingのような)決定論的空間プーリング関数を、ストライドコンボリューションに置き換えて、そのネットワークが自己の空間ダウンサンプリングを学習できるようにしたものである。
- ReLU activation は、Gで用いた(ただし出力層を除いて。出力層には tanh 関数を用いている)。
- 境界付き activation は、訓練分布の色空間を飽和しカバーすることで、モデルをより早く学習させることができることを我々は観察した。
- Dについて、特により高い解像度のモデリングにおいて、Leaky Rectifyed activatation([LeakyReLU]) が上手く動作することを我々は観察した。
- これは、maxoutを使っていたオリジナルのGAN論文とは対照的である。
安定した Deep Convolutional GAN のアーキテクチャガイドライン
- Discriminatorについては、 プーリング層をストライドコンボリューションに置き換える。
- Generatorについては、プーリング層を fractionall-strided convolution(http://deeplearning.net/software/theano/tutorial/conv_arithmetic.html#transposed-convolution-arithmetic : Transposed Convolution :逆畳み込み)に置き換える。
- 深いアーキテクチャ用の全結合の隠れ層を削除する。
- ReLU activation を G の全層(ただし出力層はTanh)に用いる。
- LeakyReLU activation を D の全層に用いる。
4 Details of Adversarial Training
- 3つのデータ・セット: LSUN, Imagenet]-1k, 新しく構成した顔画像セットを適用
- 学習データのプリプロセスはなし、ただし、 Tanh activationのための入力スケーリング `[-1, 1]` は行う
- 全モデルは、SGDミニバッチ(サイズ128)で学習させる。
- 全ての weight は、平均ゼロ、標準偏差0.02の正規分布で初期化する。
- LeakyReLUでは、leak の傾きは、0.2
- 事前のGANの動作は、momentum を使ってトレーニングを加速し、ハイパーパラメータのチューニングにはADAM最適化を使う
- 学習率 0.001は高すぎると分かったので、0.0002を代わりに使用
- leaving the momentum term
0.9 だと、トレーニング発振が置きた。0.5だと安定した
4.1 LSUN
- 画像生成モデルから生成したサンプルの視覚的品質が改善されるにつれて、過学習とメモリ化(memorization) が発生した。
- より多いデータとより高い解像度の生成で、いかに我々のモデルがスケールするのかを示すため、LSUNベッドルームデータセット(データ数300万強)上でモデルをトレーニングする。
- 最新の解析では、モデルの学習の速さと、その生成性能との間には直接的な関係があることが示されている(Hardt et al., 2015)。
- オンライントレーニングを模擬するものとして、トレーニングのある1つのエポックから得たサンプルを示す(図2)、また、我々のモデルが単純に過学習/memorizing していて高品質のサンプルを生成していないことを示すものとして、収束後のサンプルも付け加える(図3)。
- data augmentation は適用していない。

- 
-
- 図3 トレーニング5エポック後に生成した画像。いくつかのベッドのベースボードなど複数のサンプルに渡るノイズテクスチャの繰り返しが視覚的アンダーフィッティングの証拠を示している。
4.3 Imagenet-1k
5 Empirical Validation of DCGANs Capabilities
6. Investigating and Visualizing the internals of the networks
- G と D の調査
- トレーニングセット上の最近傍探索系のものは一切やらない。ピクセル空間や特徴空間での最近傍は、ちいさな画像の変形によって取るに足らない馬鹿げたものになる(Theis et al., 2015)。
- また、対数尤度(log-likelihood)メトリックは、貧弱なメトリックなので、モデルの量的評価用に使わない。
6.1 Walking in the latent space
- 隠れた空間
- 学習された多様体(manifold)の上を"歩き回る"と、メモリ化(=シャープな遷移がある場合)の兆候や、その空間が階層的に捉えられている様子について理解できる。
- もしこの隠れた空間での"歩き"が、画像生成の意味的変化という結果(オブジェクトが追加・削除されるような)を生じるなら、我々は、そのモデルが適切かつ興味深い表現を学習したことを理由づけることができる。この結果は図4に示す。
- 
-
- 図4 Z上の walking
6.2 Visualizing the discriminator features
- 画像の大きなセット上でトレーニングした教師なしDCGANも、興味深い特徴の階層を学習できることを示す。
- (Springenberg et al., 2014)に提案されたガイド付きバックプロパゲーションを用いて、 D によって学習された特徴群がベッドルームの典型的な部品(ベッドや窓のような)上で活性化する様子を図5に示す。
- 比較のためのベースラインとして、同じ図に、ランダムに初期化された特徴(それは、意味的に関係していたり興味深いものは何も活性化されない)を示した。

- 図5 右側:Dの最後のコンボリューション層の最初の6個のコンボリューション特徴の最大の軸に沿った応答の guided backpropagation 可視化。ベッドに対して応答する特徴群の顕著なマイノリティの通知ーLSUNベッドルームデータ・セットの中央のオブジェクト。左側:ランダムフィルタベースライン。前述の応答に比べて、区別がないかそれに近く、そしてランダムな構造がある。
6.3 Manipulating the generator representation
6.3.1 Forgetting to draw certain objects(あるオブジェクトを描画しない)
- Gの学習状況はどうだろうか。
- Gが生成したサンプルの品質は、以下を示唆している:主なシーンのコンポーネント、たとえばベッド、窓、ランプ、ドア、そしてその他の家具のようなものについて、特定のオブジェクト表現をGは学習している。
- これらの表現が取っている形式を調べるため、ある実験を仕立てた:Gの出力から完全に窓を取り去ろうという実験である。
- 150のサンプル上で、52の窓の境界矩形を手動で描いた。
- 2番めに高いコンボリューション層の特徴群にて、「描いた境界矩形の内側の活性化がポジティブで、かつ、同じ画像からのランダムサンプルがネガティブである」という判断基準を用いて、ある特徴の活性化反応が窓に対するものなのか否かを予測するための、ロジスティック回帰関数をフィッティングした。
- この単純なモデルを用いることで、重みがゼロより大きい全ての特徴マップ(全部で200)が、全ての空間位置から脱落した。そして、ランダムな新しいサンプルがその削除された特徴マップで/生成された。
- 窓あり・なしで生成された画像を図6に示す。そして、興味深いことに、このネットワークは、ベッドルームの窓を描くのをほとんど忘れていて、他のオブジェクトで置き換えている。

- 図6
6.3.2 Vector arithmetic on face samples
- Word2Vec のような構造が Zの表現の中にあるか調べた。
- 視覚的概念ための お手本サンプルセットのZベクトル上で、同様の演算を行った。
- 1コンセプトにつき単一のサンプルによる実験は不安定だが、3つの手本についてZベクトルを平均化すると、一貫して安定した意味論的に演算に従う生成が見られた。
- 図7に示すオブジェクト操作に加えて、顔の姿勢もZ空間内で線型にモデル化されていることを示した(図8)。
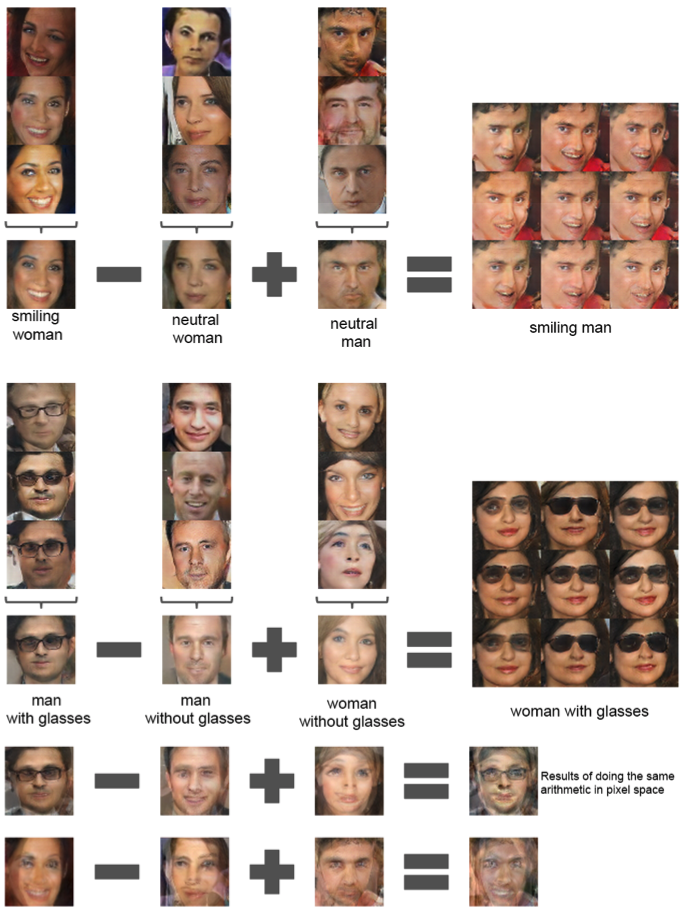
- 図7
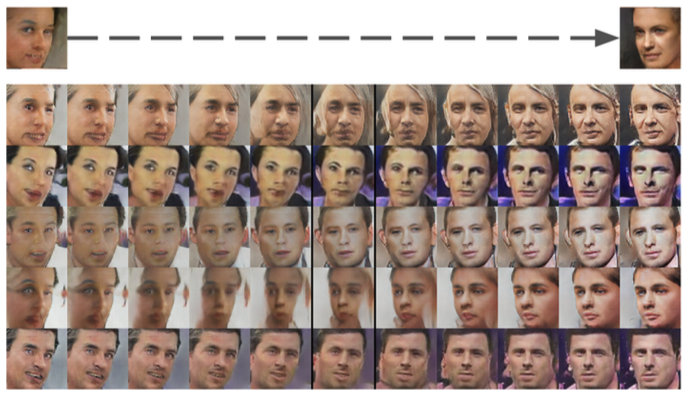
- 図8
個人的記録:訪日タイ人向け Edamameサービス停止&技術メモ
昨日、2017/10/31を持ってオープンストリームのEdamameサービス・アプリを事業終了しました。技術開発&事業開発を推進してきた者として非常に残念かつ寂しいですが、当初の事業目標(KPI:アプリダウンロード数)を達成しなかったためであり、これは仕方のないことです。

図:Edamameアイコン
ここでは、Edamame開発を通じて獲得できた技術ノウハウについて記録しておきます。Edamameの技術的基本コンセプトは、生産性に寄与すると思われる技術は、新しいものでもドンドン積極的に導入して実験場とすることでした。
Edamameで獲得できた技術
Edamameシステム開発で獲得できた新しい技術は主に以下のものです。短期間に最少人数で獲得できた技術としてはなかなかのもの、でしょうか?
- iOS Swift2.x, 3.x プログラミング
- クロージャ積極活用による非同期プログラミング
- Nullセーフプログラミング
- 例外処理を使わないエラー処理
- Apache Thrift による、WebAPIトランスポートの自動実装
- クライアント側はObjective-C、サーバーはJava側へと自動コード生成
- SwiftからObjective-Cのブリッジ実装およびエラー伝搬方法
- Servlet への組込み方法
- CocoaPods の利用方法
- MongoDBプログラミング
- Amazon AWS ベースの開発・設計ノウハウ
- Spring(Boot)による、Web管理コンソールの開発
- Thymeleafによるテンプレート実装、高度なネスティング記法の活用
技術・設計評価
最もインパクトが大きかったのが、Apache Thrift の採用でした。最初の導入には少々苦労しましたが、作業が安定してからの威力はすごかったです。WebAPIの開発生産性を飛躍的に高めてくれました。なにしろ、APIを追加・修正してもサーバ側・クライント側双方のトランスポートコードが自動生成され、接続性が保証されていますから、疎通テストが不要で、本来のロジック開発に集中できました。
また、Thriftはエンジニアチームの構成にも良い影響がありました。実装に参加したプログラマを、クライアント側・サーバ側といった風に分ける必要がなく、いわゆるフルスタックエンジニア的に、両方のコードを垣根なく行き来して開発ができるようになったのです。このため機能追加やデバッグの効率が非常に良くなりました。Swift とJavaの両方を書ける能力は必要ですがw。
二番目にインパクトが大きかったのは、アプリ側のSwift採用です。チーム全員未経験でしたが、チュートリアルからスタートして一気に学習し、マスターできました。やはりObjective-Cに比べて、コーディングの効率・見通しの良さが格段に違います。
三番目にインパクトが大きかったのは、フルMongoDBによるDB構成です。RDBがなくても問題なくサービス運用できることを実証できましたし、スキーマーレスなので、運用中にサービスを一切止めることなく項目追加をすることも可能でした。
Edamameは 事業としては失敗でしたが、技術的には得るものが多く、その後の「ねこもに」にそのノウハウや人材を流用できていますので、当社として一定の投資効果があったと言えると思います。
IoTが本格化すると、特許問題が深刻になりかねない?
IoT時代は、特許侵害が可視化されやすくなる
ねこもにの特許取得を通じて、あらためて最近の特許の動向を調べていて気づいたのですが、これから IoT が本格的に立ち上がってくるとすると、ソフトウェア開発業界にとって、特許の問題が従来に較べてはるかに大きくなる懸念があります。
日本の特許制度では、ソフトウェアやアルゴリズム単体の発明では特許にはならないため、長らくソフトウェア開発業界ではほとんど特許の事を気にしていませんでした。しかしIoT時代では状況が一変してきます。
IoTは直訳して「モノのインターネット」ということで、物理世界のデバイス・ハードウェアをICTソフトウェアと連携させることで、新たな価値を生み出そうとするコンセプトですが、そこでは、以下のような状況が生じてきます。
- ソフトとハードを連携させるので、そこに独自の工夫(新規性・進歩性)があれば特許化が可能。
- いわゆるIT系企業だけでなく、製造や物流など他業種からもIoTビジネスへの参入が増える。
- 特に製造業では、ノウハウを特許化するのは当然という文化があるので、IoT関連でも当然特許を取得する。
- IoTはいま注目の分野なので、特許をもつ権利者からも目をつけられやすい。
- ソフトだけならブラックボックスで見えなかった手法が、ハードという「外から見える」要素が加わることで、特許侵害を発見されやすい。
このような状況が揃ってくると、当然予想されるのはIoT関連の特許紛争の増加です。特にシステム開発で特許侵害問題が発生する可能性が高まるでしょう。
例えば、いままでのようにソフト開発会社がユーザ企業に言われるがままに、無自覚にIoTシステムを開発した結果、後でそれが他社の特許侵害となっているというケースなどです。
そうした事態を想定した免責条項を加えた契約をクライアントと結べていれば良いのですが、そうでなければ、システムを設計した開発会社の側にリスクのしわ寄せがくるかもしれません。ユーザ企業にしてみれば『他社の特許を侵害するような設計をするのが悪い』というわけです。
ソフト開発業界の特許への対応状況
ここでは、参考値として、J-PlatPat を使って、いくつかのソフト開発企業の特許状況を調べてみました。これはその企業の特許への取り組み・認識度をある程度反映した数値ではないかと思われるからです。
| 出願人名 | 特許出願数 | 特許成立数 |
|---|---|---|
| ウルシステムズ | 9 | 0 |
| クラス・メソッド | 0 | 0 |
| TIS | 33 | 13 |
| 富士ソフト | 76 | 46 |
| 新日鉄住金ソリューションズ | 42 | 71 |
| 日立ソリューションズ | 887 | 617 |
(2017.10.23現在)
日立ソリューションズさんは、圧倒的に数が多いですね。これは日立製作所さんの文化を受け継いでいる面が強いのでしょう。
どのような対策が考えられるか
ソフト開発における特許紛争を防ぐには、開発プロジェクトのレベルで考えると、以下のような方法が考えられます(あくまでも、これは私見です。他にもあるかもしれません。実際のプロジェクトでは特許法務の専門家と相談することを強くおすすめします):
- 1. 企画段階または設計終了段階で特許調査を行う(パテントクリアランス)
- (a)開発会社側で特許調査を行う(調査費用発生)
- (b)ユーザ企業側で特許調査を行う
- 2. 特許調査で特許侵害を発見した場合:
- (a)設計はそのままで、権利者と開発会社が実施契約を結ぶ(実施料の支払い)。
- (b)設計はそのままで、権利者とユーザ企業が実施契約を結ぶ(実施料の支払い)。
- (c)設計変更をして特許を回避する。設計変更のための追加工数発生。
- →この変更案は自社特許として出願しておく。いわゆる防衛特許です。
- 3. 顧客との契約に、免責条件を盛り込む。
- (a)一切の特許リスクを開発会社は負わない、とする。(現実的には難しいかも・・・)
- (b)なんらかの条件のもと、特許リスクを按分する:
- 例: 設計レビューに顧客も参加し、承認のうえ実装するという前提のもの、特許リスクを顧客側にもシェアしてもらう。
上記の1-(a)のパターンは、B2B的なプロジェクトではよくありそうです。1-(b)は、B2B2Cなどで、開発会社が開発したシステムをOEM的にユーザ企業が顧客に販売するケースなどで発生するかもしれません。
実はどんどん増えているIoT特許
以下の文献などがとても参考になりますが、すでにIoT関連の特許取得はどんどん増えてきています。それらの内容をみると分かりますが、『普通にシステム設計をしていけば、同じような構成になるかもしれない』と思うような特許も多数あります。いわゆる『基本特許』的な色彩が強い特許です。これはある意味で危険な兆候と言えるでしょう。上述のように、安易に設計すると気づかない間に特許侵害をしてしまう可能性が高くなるからです。

IoT特許事例集2016: ?2016年登録特許20万件からIoT基本特許48件を厳選
- 作者: 木下忠,赤堀浩司,高橋亨,佐藤規行,宮田和彦
- 発売日: 2017/08/10
- メディア: Kindle版
- この商品を含むブログを見る
ディープラーニング:RNN, LSTM, Attention 等について日本語で読める本

ねこもに、で特許をさらに出願してみた:分散協調型IoT位置推定
本日当社よりプレスリリースがでましたが、ねこもに関連で特許をもう一つ出願してみました。これは、昨年出願したものの続編というか、拡張版のようなものです。
詳しくはここには書けないのですが、もちろん類似の先行事例があるクラウド型のBLEタグの位置推定とはちょっと違うアイデアを盛り込んでいます。(じゃないと特許になりません。)ヒントは分散・協調です。
ちょっと脱線しますが、位置推定に限らず、『クラウド上の「プラットフォーム』にIoTデータを集約して、そこで解析やら可視化をすればOK』という発想は、じつはIT屋さんがよく思いつくありきたり(失礼!)なもので、あちこちで似たようなものが提案されています。IT屋さんには嬉しいアーキテクチャなのかも知れませんが、ユーザメリットをどう出すのか判然としないものが良くあります。
かつて1990年代に花王が仮想工場に取り組もうとして失敗したという歴史があります。これはいまでいうIoTやIndustry4.0に相当する先進的なものでしたが、失敗の大きな原因は通信コストだと言われています。この問題は現在でも潜在しつづけているのではないでしょうか。大規模なIoTを展開しようとすれば、この通信費の問題は必ずついて回ります。いまならソラコムさんあたりがなんとかしてくれるかもしれませんが。